Well, I was
working on a research project to see if I can design a CSV extract parser for
the Planning metadata extract and since Java is my poison, I was using it to
see if I could design a slightly UI based metadata parser…
But, it was
slightly more fun than that…
Now, when we
say that the Planning metadata extract is a CSV file this is what we all assume
it to be…A file that is delimited by commas for fields and although it may span
across multiple line, it will still be one line that has been text wrapped…
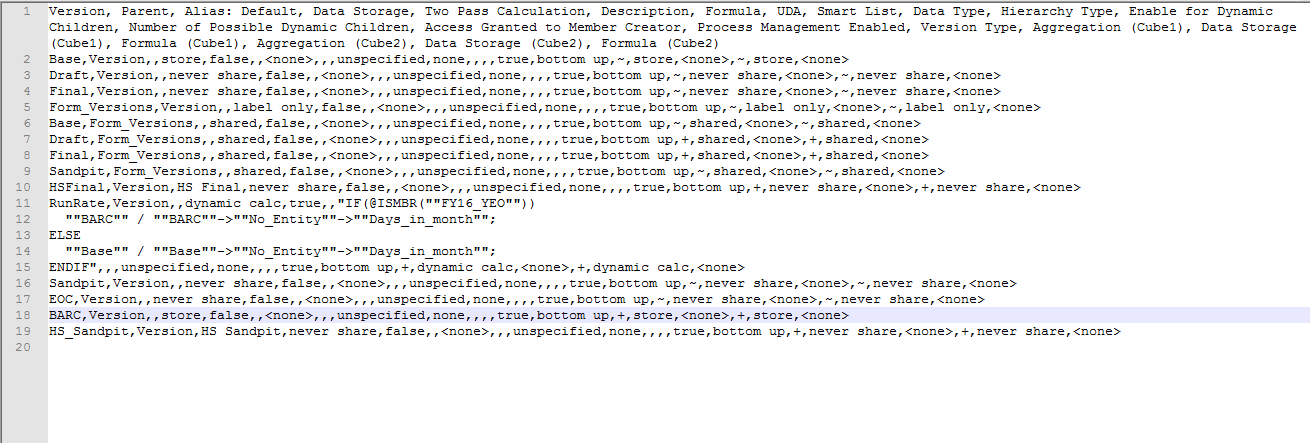
Now this is the file that I was using for testing the metadata parser…This was a good example…Perfect example of a good test case because hardly 20 lines exposed a new flaw…
I was using
the Java function split() to break a line into different tokens and then
mapping it to the first line which is a one-to-one mapping of the fields…
However,
when my program ran on line 12, I got an ArrayIndexOutOfBoundsException… This
happens when you try to read an element with an index whose value is greater
than the last element index… i.e if the array has size 10, if I try to read the
20th element in the array I will get an
ArrayIndexOutOfBoundsException…
Now, let us
look at the offending line…
The metadata
spans across multiple lines if you have an “if” formula tagged to a member in
the CSV extract…The main assumption about the extract goes to toss that a
single line represents all information of a member… New solution needed alert…
So, now I
had two questions regarding the extract…
- How does Planning read the extract?
- How does it know if it has met a line delimiter or a field delimiter?
Now, since I
am using Notepad++, I tried to see what the delimiters are… Below is the same
file with the delimiters being shown…

Observe the
delimiters in the file for line 11 to 15… Line number 11 has a line feed as a
delimiter and line number 15 has a line CtrlR+Line Feed as a delimiter…
Mystery
solved… Planning CSV parser uses a Ctrl R + Line Feed to indicate the end of
record… A simple line feed indicates that more of the records is present on the
next line…
This is a
problem with different delimiters being used for different environment…In some
systems line feed may be a single character whereas in others (Windows), line
feed is made up of two characters…
(Interesting
fact that explain why we need two characters for newline traces back to
printers and type writers… Talk about old school… In a typewriter, a new line
consists of motion across two axes…Down and to the left…That is why you need
two characters for newline in some system…However, for a software system we can
combine these two into just one special character)
Now, I was
using Java and thought that I will read a line using the readLine() function,
but catch with this is that if you use readLine(), Java will trim the
end-of-line delimiter… This means that the Planning CSV parser reads the
extract at a character level and parses the extract when it meets the
end-of-line character…

I am still
working on the CSV parser…Need to test it for all ifs and buts and improve the
UI a bit…
No comments:
Post a Comment